How to Save a Small Fortune by Buffering Less.
While working for a large client processing several petabytes of data per month, I had the opportunity to attack the primary ingest service with YourKit.
This service is written in Scala and Java and runs on giant expensive AWS instances due mostly to the heap requirements, but also to keep plenty of CPU headroom as this client is performance-sensitive.
The first thing I noticed was most of the heap usage was generated in one small spot: a custom InputStream that performs a checksum on the data. It was issuing a read() with a buffer size of 5MB. Conventional Java wisdom says anything beyond a fairly small buffer is usually a waste, and we confirmed this with simple benchmarks. We ended up dropping this to 8k with absolutely no performance degradation. The result of this single change is dramatic:
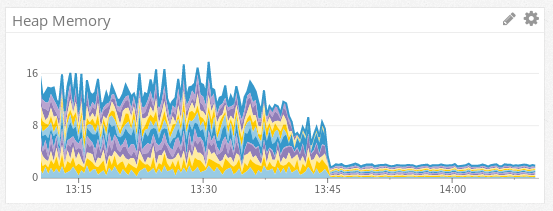
The second thing I noticed with this piece of code was that it was doing date calculations inside the read loop in order to support a debug logging statement that was normally disabled. Getting the current time requires a relatively slow system call to make in a tight loop. We removed this code as superfluous.
Third, to add insult to injury, YourKit made it obvious that the AWS SDK had debug logging enabled but output disabled. So, while there was no actual debug log output, very expensive debug statements were being evaluated. We deployed a log4j.properties to shut this off and, with the time calls also removed, saw our CPU usage drop in half and our performance double:
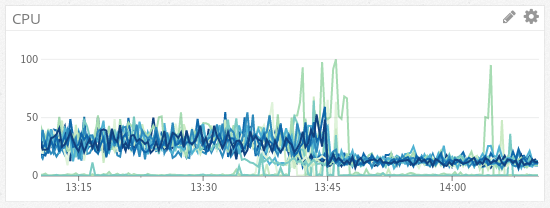
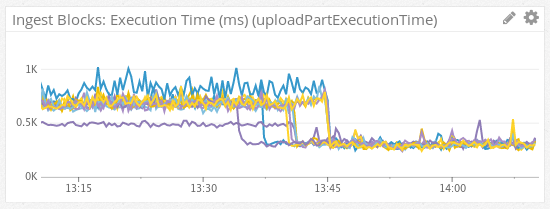
As a result of a day or so of profiling, tuning, and testing, we were able to downsize an entire fleet of expensive instances saving many thousands of dollars per month while still providing better performance.